文章目录
概述
RTA 即Realtime API的简称,是一种实时的广告程序接口,用于满足广告主实时个性化的投放需求。RTA 将流量选择权交给广告主,通常在定向环节中将用户身份的识别的请求发送给广告主,进行用户的筛选。
最近几年国内越来越重视用户隐私,许多之前用的很顺手的操作(比如上传人群包)在现在就得斟酌下了。RTA是解决这类问题的一个好方案。RTA可以在不上传人群包的情况下完成人群定向,同时可以结合产品数据进行实时调整,非常灵活。
RTA能帮广告主做到如下事情:
- 流量筛选
- 投放控制
- 出价干预
其中第三点需要媒体的支持。
RTA业务流程
每次⼴告请求参与竞价时, 平台携带用户信息请求⼴告主服务器, 广告主判断此次请求是否参竞,平台根据广告主返回结果进行定向流量竞投。
流程图如下:
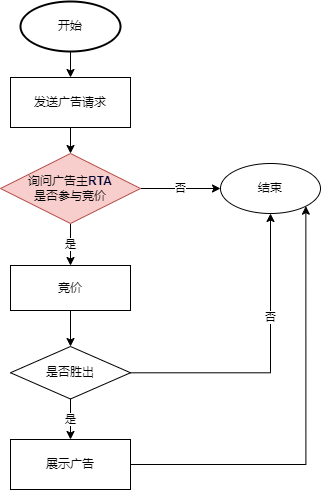
根据上面的流程图可以看出RTA主要是在媒体的DSP或SSP接收到流量后,执行竞价逻辑前发挥作用。
RTA引擎处理流程
先来看下整体的处理流程图:
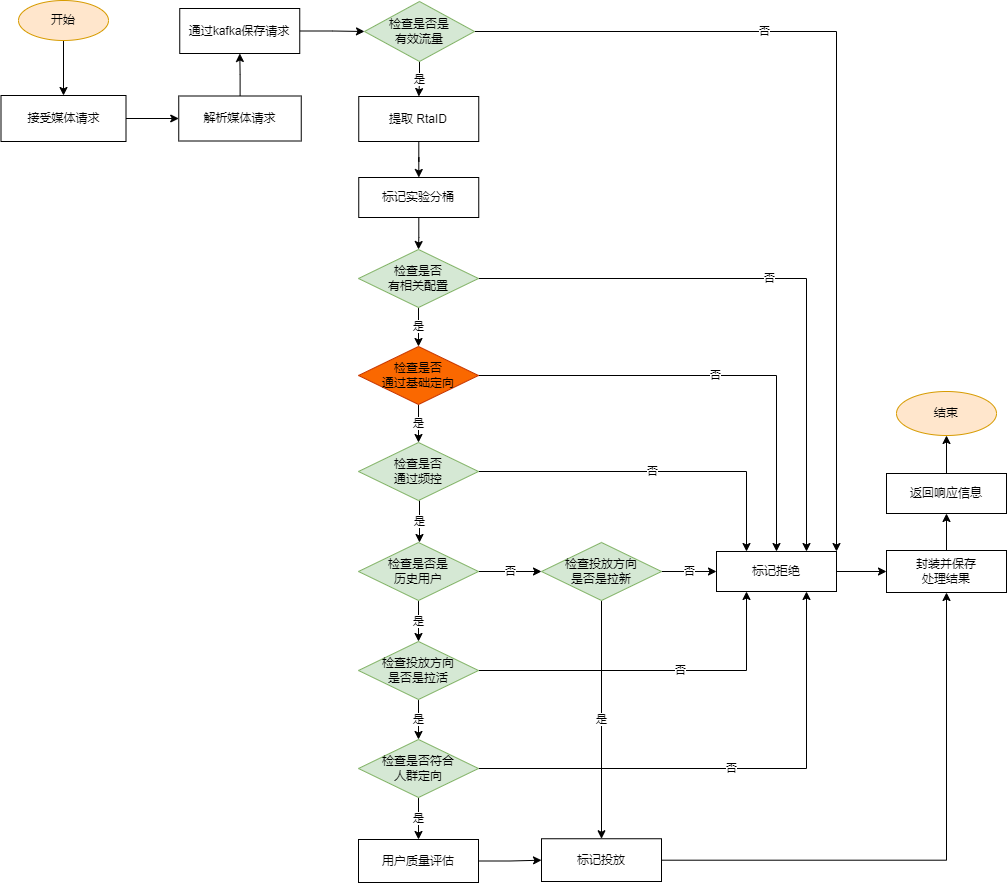
我们使用RTA对拉新和拉活的流量都有做筛选。
对于拉新只能利用请求中的信息做基础定向或者使用曝光/点击的数据进行曝光/点击频控。不过如果有采买第三方的数据,就还可以多做些事情。
对于拉活,可以基于历史数据和实时的曝光/点击/UV数据做如下事情:
- 基于请求中的IP/经纬度/年龄段等信息做基础定向筛选
- 投放频控:曝光频控,点击频控,UV频控(天/月/效果)
- 人群包定向
- 根据用户质量控制出价
再来简单说下流程图中的几个关键节点:
- 检查是否是有效流量:因为我们的后续判断主要是根据设备ID来做的,所以不包含有效设备ID的流量就会被视为无效流量,当然还有一些测试流量也会被标记为无效流量
- 提取RTA_ID:RTA_ID标识一行RTA配置,每个RTA请求中都会包含一到多个不同的RTA_ID(比如头条),如果请求中没有RTA_ID(比如百度),则取对应媒体在广告主端配置的全部RTA配置
- 标记实验分桶:对设备ID做Hash运算后执行求余运算进行分组,分组信息会记录在请求及响应日志中,为后续的数据计算和分析提供依据
- 检查配置:根据RTA_ID检查是否有做相关配置。配置数据存放在MySQL中,RTA引擎会启动一个协程每3分钟从MySQL查询全量配置保存到内存
- 基础定向检查:基于请求中的IP/经纬度/年龄段等信息做基础定向筛选,这一点在媒体那边也能完成,且更精准,故在这里仅做了规划,没有实现,在流程图中用深色做了标记
- 频控检查:根据设备ID来判断当前用户是否被做了频控。需要被频控的设备ID通过RTA引擎外部的实时任务或定时任务计算得到,频控的数据早期存放在redis缓存中,后期通过kafka将需要做频控数据发送到RTA引擎内存中
- 历史设备检查:通过检查是否是历史设备来决定是做拉新投放还是拉活投放。我们有维护历史设备库,仅需要根据设备ID判断该设备是否在历史设备库中就可以判断该设备是否是历史设备。历史设备库中的有效设备总量约为3.5亿,直接通过MySQL查询对MySQL数据库将是一场灾难,而把这些数据直接放在RTA引擎内存中或redis内存中也会有存储压力或查询压力,故我们在RTA引擎内部维护了一个CuckooFilter(CuckooFilter)来存储全量历史设备数据,这些历史设备数据在内存中占用的空间约为2G
- 人群定向检查:拉活投放不是只判断了是历史设备了就可以投放了,还有更细粒度的需求,比如针对七日人群或城市人群或指定年龄段人群进行投放,这些数据的规模一般也就是百万级,可以直接存放在Redis中
- 用户质量评估:头条是支持用户质量分和出价系数的,这两个信息反映了用户对 广告主的价值,通过这两者广告主可以在一定程度上干预出价。算法同学会结合已有数据计算出每个历史用户的的质量分和出价系数,并将之保存到redis中。使用时只需要根据设备ID查询获取即可。
以上就是RTA流程中的关键节点了。其它部分参考前面的流程图就行。
RTA引擎和其他服务的关系大致如下图:
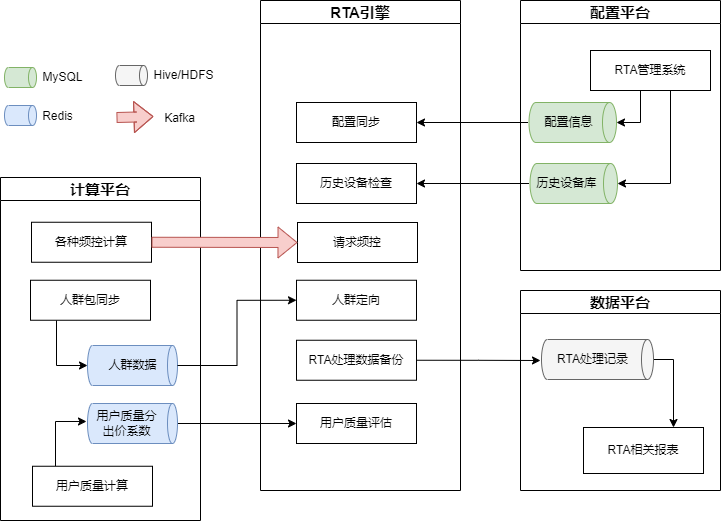
遇到的问题
接下来介绍下RTA运行中遇到的各种问题及解决方案。
1. 请求规模问题
媒体一般要求RTA的处理时间在30ms以内。目前我们的RTA每天接收到139亿个请求,QPS峰值约为35w,这个规模的流量给我们造成了一定的压力。
RTA服务部署在腾讯云上,共60个节点(每个节点16核32G),走的腾讯云的四层负载均衡TGW(TGW基础原理)。有两个TGW VIP节点通过加权轮询的方式将流量引向RTA的节点。
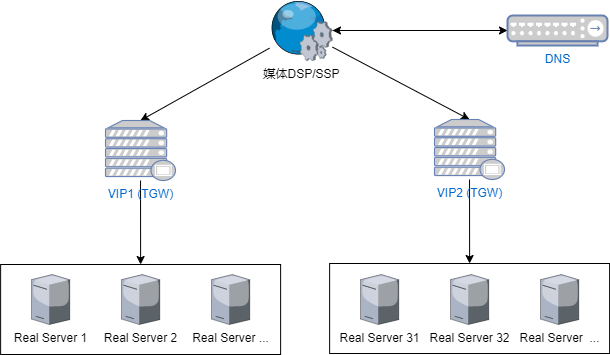
不过应该是由于DNS缓存的问题,请求并不能均匀的转发到两个TGW的VIP上。抽样检查了一个小时的请求量,发现两个VIP对应的节点约有20%的差距。
此外RTA相关的一些基础服务比如Redis是部署在公司自有机房内的,导致只是跨机房请求就会有2ms的时间消耗。
再来说下是怎么应对这些流量的。
在设计RTA引擎的时候我们就确定了一个思路:尽量减少网络请求。目前系统依赖的外部组件有Redis和MySQL。因为只启动了一个协程定时从MySQL中同步配置信息,所以MySQL的压力可以忽略。
Redis中存储的是人群信息,这部分查询是不能避免的,但是据我们的经验,redis最多能承受5~6wQPS,再多了就会出现CPU使用率过高的报警。因为拉新投放不用请求redis,所以处理流程中的“历史设备检查”这个环节是非常重要的,有了这个环节,需要打到redis的流量会被压缩到3wQPS左右。最后,我们还启用了本地小时级缓存,从redis查询到的数据都会在本地缓存,这样对redis的请求会再次被压缩。
另外,我们还做了应用内限流,采用的是简单计数法,当每秒内请求总数超过5500之后再来的请求就会被丢弃掉。
2. 媒体数据质量
在投放完成后还需要回收相关数据作为算法迭代的素材。这就需要将RTA收到的请求数据和后续的曝光点击数据连接起来,依据在RTA请求处理中做的实验分组进行效果对比和评估。
最开始我们做的连接是流量级别的连接,但是因为种种缘故,曝光和请求数据的连接率始终都不够好。期间也有和媒体做过多轮沟通,但是最终曝光连接率也只能提升到70%左右。
最后我们放弃了流量级别的连接,采用了宏观的分组方案,即分别在请求/曝光/点击几层按相同的逻辑进行分组计算,然后按整体比例进行统计和分析。经过实验,结果和预期还是比较匹配的。
3. 头条设备ID加密带来的问题
这个问题是由近期头条的一次升级带来的(升级的背景在这里)。
因为头条在发送的RTA请求中不再提供原始设备ID或原始设备ID的MD5值,我们也只好用加密设备ID来和他们匹配,这样就导致全量历史设备库规模会变成之前的三倍(原值MD5值,原值加密值,原值MD5值加密值)。为了使RTA的不至于误判,就需要同时增加CuckooFilter的规模,加上备份CuckooFilter所需的内存空间,最终产生了OOM问题。
最终沟通出来的解决方案是为头条站内请求只保留近一年的历史设备数据,而其他媒体仍使用全量的历史设备库。通过这样的折中方案暂时解决了问题。
目前就这些问题。之后如果再想到会补上。
END!!!
老哥我也是做rta的能聊一下吗?
目前已经不做RTA了
可以加微信沟通沟通 吗